 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneNAT: Masked Generative Modeling for Language-Guided Indoor Scene Synthesis
Jan 12, 2026We present SceneNAT, a single-stage masked non-autoregressive Transformer that synthesizes complete 3D indoor scenes from natural language instructions through only a few parallel decoding passes, offering improved performance and efficiency compared to prior state-of-the-art approaches. SceneNAT is trained via masked modeling over fully discretized representations of both semantic and spatial attributes. By applying a masking strategy at both the attribute level and the instance level, the model can better capture intra-object and inter-object structure. To boost relational reasoning, SceneNAT employs a dedicated triplet predictor for modeling the scene's layout and object relationships by mapping a set of learnable relation queries to a sparse set of symbolic triplets (subject, predicate, object). Extensive experiments on the 3D-FRONT dataset demonstrate that SceneNAT achieves superior performance compared to state-of-the-art autoregressive and diffusion baselines in both semantic compliance and spatial arrangement accuracy, while operating with substantially lower computational cost.
RGB-D Mapping and Tracking in a Plenoxel Radiance Field
Jul 07, 2023Building on the success of Neural Radiance Fields (NeRFs), recent years have seen significant advances in the domain of novel view synthesis. These models capture the scene's volumetric radiance field, creating highly convincing dense photorealistic models through the use of simple, differentiable rendering equations. Despite their popularity, these algorithms suffer from severe ambiguities in visual data inherent to the RGB sensor, which means that although images generated with view synthesis can visually appear very believable, the underlying 3D model will often be wrong. This considerably limits the usefulness of these models in practical applications like Robotics and Extended Reality (XR), where an accurate dense 3D reconstruction otherwise would be of significant value. In this technical report, we present the vital differences between view synthesis models and 3D reconstruction models. We also comment on why a depth sensor is essential for modeling accurate geometry in general outward-facing scenes using the current paradigm of novel view synthesis methods. Focusing on the structure-from-motion task, we practically demonstrate this need by extending the Plenoxel radiance field model: Presenting an analytical differential approach for dense mapping and tracking with radiance fields based on RGB-D data without a neural network. Our method achieves state-of-the-art results in both the mapping and tracking tasks while also being faster than competing neural network-based approaches.
Keeping Less is More: Point Sparsification for Visual SLAM
Jul 01, 2022
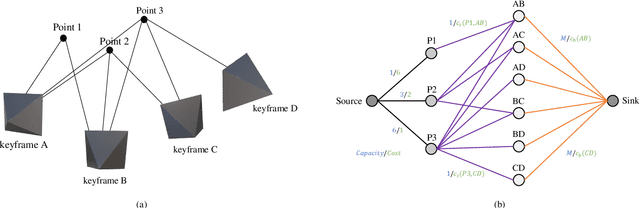
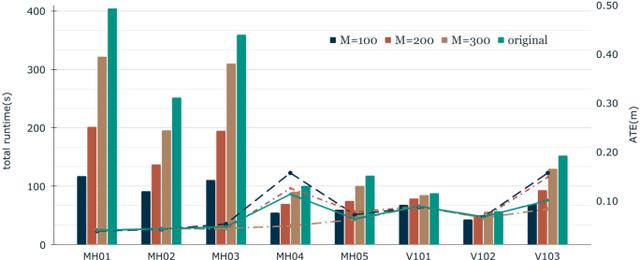

When adapting Simultaneous Mapping and Localization (SLAM) to real-world applications, such as autonomous vehicles, drones, and augmented reality devices, its memory footprint and computing cost are the two main factors limiting the performance and the range of applications. In sparse feature based SLAM algorithms, one efficient way for this problem is to limit the map point size by selecting the points potentially useful for local and global bundle adjustment (BA). This study proposes an efficient graph optimization for sparsifying map points in SLAM systems. Specifically, we formulate a maximum pose-visibility and maximum spatial diversity problem as a minimum-cost maximum-flow graph optimization problem. The proposed method works as an additional step in existing SLAM systems, so it can be used in both conventional or learning based SLAM systems. By extensive experimental evaluations we demonstrate the proposed method achieves even more accurate camera poses with approximately 1/3 of the map points and 1/2 of the computation.